Logistics Today:https://www.logi-today.com/339954
配送進捗把握しやすく、スマート動態管理に新機能
|
LNEWS:https://lnews.jp/2019/04/l0409304.html
オンラインコンサルタント/配送状況の進捗管理機能、スマホ用を開発
|

ありがとうございます!!!⊂(^-^)⊃
Logistics Today:https://www.logi-today.com/339954
配送進捗把握しやすく、スマート動態管理に新機能
|
LNEWS:https://lnews.jp/2019/04/l0409304.html
オンラインコンサルタント/配送状況の進捗管理機能、スマホ用を開発
|
ありがとうございます!!!⊂(^-^)⊃
本日、10時にこちらのプレスリリースを行いました!
プレスリリースの本文は、ご興味があればぜひ読んで頂きたいのですが、平たく申し上げますと下記のような感じです。
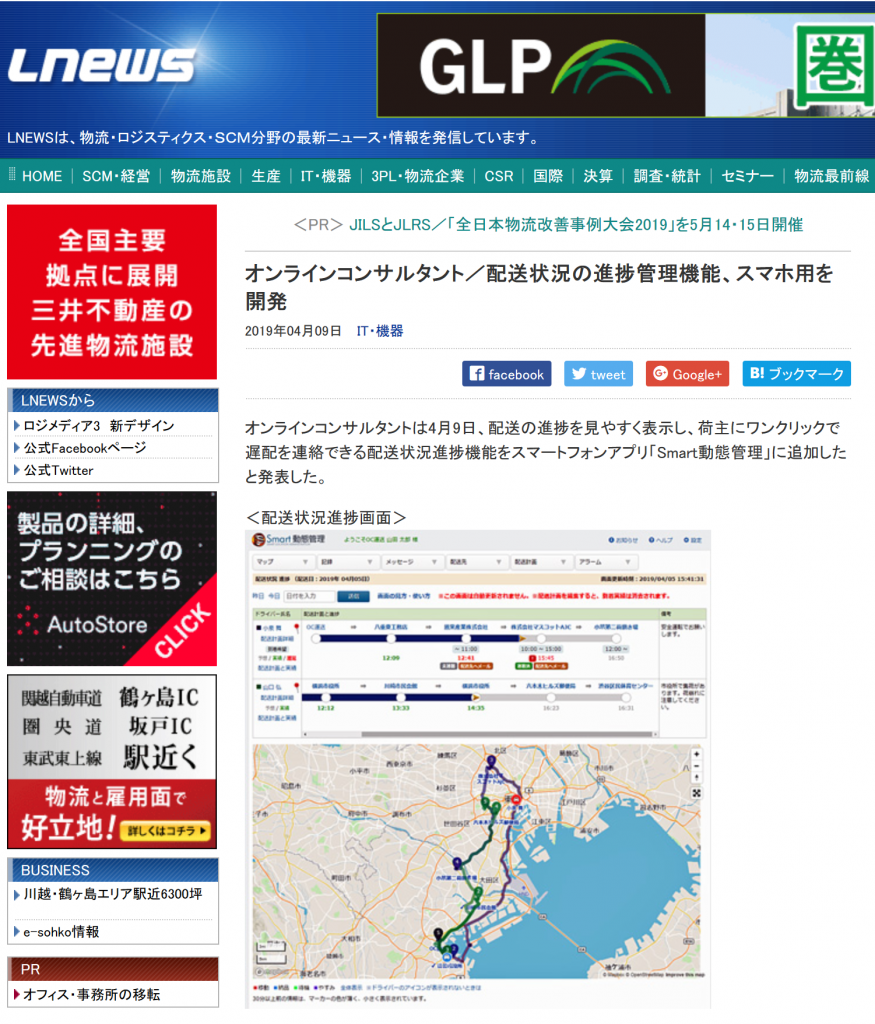
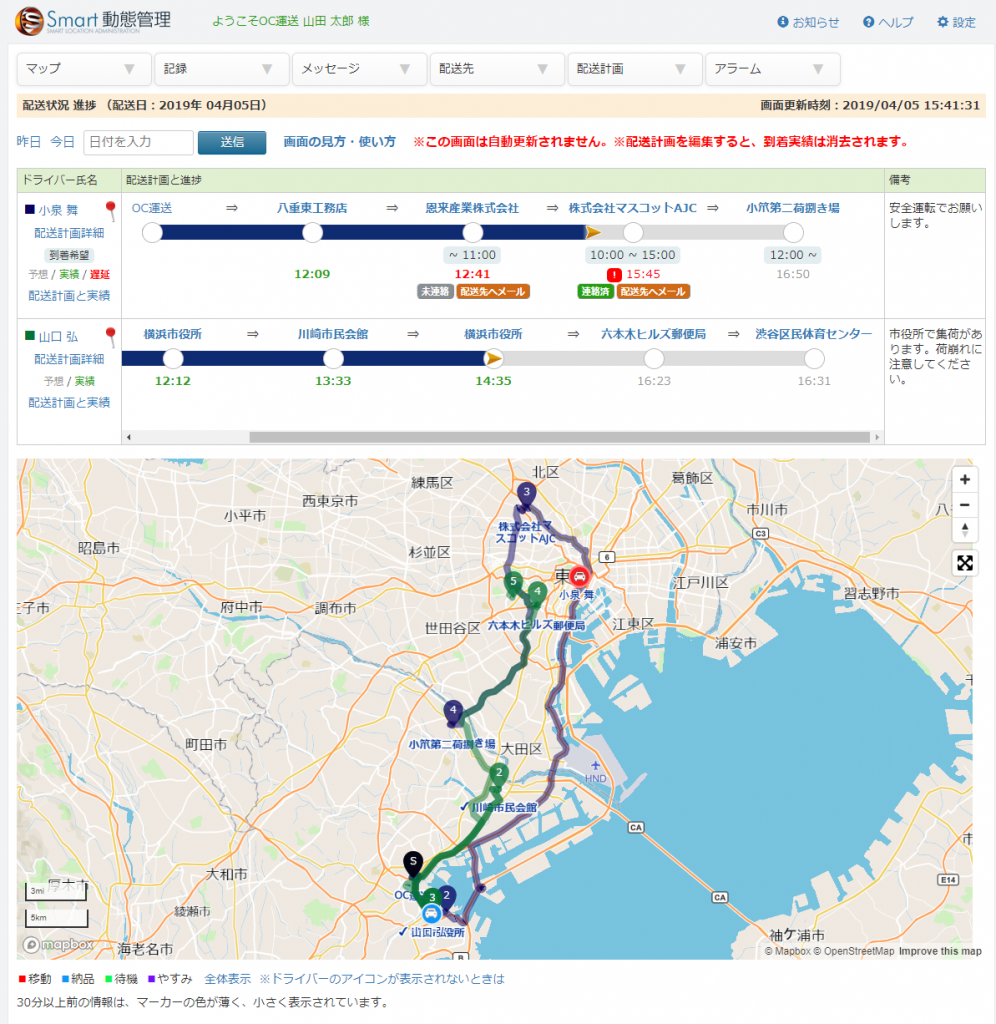
Smart動態管理に、配送状況の進捗管理機能が追加されました。
何時にどこへ何を配達する、ということで配送を行っていらっしゃる配送会社さんは多いと思いますが、渋滞などで遅れてしまう場合、ドライバーさんが携帯で運行管理者か、荷主に電話する、ということが多いんですよね。
しかし、それではドライバーさんは一時停車しないといけないですし、たまたま先方がいらっしゃらないなどだと、折り返し…などになり、大変手間です。
もちろん、それで止まってしまうので、配送自体がもっと遅れてしまいますよね。
なので、この遅れを電話などは不要に運行管理者さんが視覚的にすぐにわかる、というのが今回の配送状況の進捗管理機能なのです。
ドライバーさんの位置情報は、スマホにインストールしたSmart動態管理から、最短10秒間隔で送られてくるので、ほぼリアルタイムで運行状況がわかります。
また、運行管理者さんにとっても、画面でドライバーさんの遅れがわかり、さらにワンクリックで荷主さんにメールができるという機能があります。
この機能は、若手のN君が代表で作ってくれました! 結構長い開発期間で、お疲れ様です。⊂(^-^)⊃
連日、運送・配送業界での人手不足の問題が新聞やニュースをにぎわせています。
ドライバー不足は、業界が抱える深刻な問題です。
こういった、日々の業務を効率化していきたいですよね。
Smart動態管理にて、アンケートを時々行っています。
今回、株式会社西山醤油店様よりご回答を頂きました。ありがとうございます。⊂(^-^)⊃
機能がよい、と言っていただけることはもちろん、サポートが親切、というのはうれしいですね!
西山醤油店様を担当しているMも、うれしさのあまりガッツポーズをしておりました。( ˊᵕˋ )
それを見て、私も大変うれしいです!!(๑>◡<๑)
常々思っていることなんですけど、カスタマーサポートって本当に難しいですよね。
これは話が長くなりそうなので、別の機会に書こうと思います。

今日が今年度最後の営業日ですね!!!(`・ω・´)
えー、1か月ブログ書いておりませんでした…。
手からギャリック砲が出るほど忙しくって…(>_<)
年度末で仕事が忙しいのに加え、自宅の引っ越しとか、旅行×2とかでしたね!!!
しかし、このニュースだけは!!!!口を出したかった~
https://headlines.yahoo.co.jp/hl?a=20190322-00000024-zdn_n-sci
ゼンリンとGoogle決裂…っ!!
これは業界に激震ですね~(`・ω・´)
しかも!!!なんとゼンリンの提携先はMapbox!!!!!
おおー。
MapboxがまだまだOSMに毛の生えた感じだったころから使い続け、じゃっかん普及活動みたいなことをしてきた私としては、日経新聞とかYahooニュースにMapboxの名前が載るだけでも感無量です。(つД`)
私の普及活動の2例を…
しかし…。
喜んでもいられない…。
逆に、Mapboxが高くなってしまうかもしれない。((((;゚Д゚)))ガクガクブルブル
Mapboxに問い合わせたところ、今のところ値上げなどはないらしいですが。
というか、このニュースは裏を返せば、Googleさんが、
「もうゼンリンの手を借りなくても、自分たちで地図作れるわ!!!ウワハハハ」
ということだと思うのですよ。
ゼンリンさんって、昔聞いた時は、調査員という方が全国にいっぱいいらっしゃって、その方たちが歩いて地図を作っているそうなんですよね。
なので、細かい路地を入ったところが林さんのお宅だ、などという情報がわかるんですね。
簡単に端的に言いますと、人海戦術みたいなところがあります。
Googleさんは、スマホの位置情報などを使ってるんでしょうか。
そして、Mapboxは、元々Open Street Mapという、地図をみんなで作っていこう、というプロジェクトのデータを今までは使っています。
地図のWikipedia版みたいなもんですね。
私は、個人的にはこの陣営に乗りたかった。
そして、それってすっごい大切なことなんですよね~(`・ω・´)
なので、これからは人海戦術よりもオープンソースの地図だろ~ と思ってたわけです。
また、心情的に常にジャイアントキリングに挑む会社や人を応援したいですね。
だからって採用しているわけではないですが…。
しかし、人海戦術とオープンソースがどう合体するのか…。
そして、Googleの地図の精度がどうなるか…
また、今までGoogle mapはオフラインだと使えない、法人利用が高額、印刷できないなどの縛りがあり、これが全部ゼンリン由来だと言われていましたから、この弱点が克服できたらGoogle Mapの方が強いのかもしれません。
弊社の仕事に密接にかかわる点なので、興味深くウォッチしていきたいですし、なんか情報などあれば、ぜひ教えてください。m(_ _)m

日経産業新聞(2019年2月8日号)で、弊社の配送計画作成機能が取り上げられました。

配送業界は、今いろんなテックカンパニーが参入してきてますね…。
なんとか再配達を防ぎたい…というのは業界の課題ですよね。
配達してもらう予定を先に配達してもらう方が指定できるといいんですけどね。
友達が家に遊びに来るとき、こちらの予定も聞かずにいきなり来るのは、あまりないじゃないですかw
せめて、漠然とでも
「平日なら夜6時以降ならいる」
ぐらいでこちらの予定を入力しておくとかで調整できるといいですよね。
納品をお願いしていた仕事について、メールしても連絡がないので、電話してみたら
「この電話番号は現在使われておりません。番号をお確かめの上…」
という久々に聞くアナウンスが。
大した仕事をお願いしていたわけでもないし、前金を振り込んでいたわけでもないから、被害は少なかったんですが。。。
まじかー。
ってなりましたね。
ちなみに、これは1月末の話です。
12月末には社長さんに会って、
「うち今いろんなビジネスやってて~ これも~ あれも~ うまく行ってるんですよ」
みたいに紹介されたんですけどね。(´ω`)
お正月あけぐらいまで連絡あったんですけどね。(´ω`)
中小企業社長の
「うまくいってる」
は信じてはいけないw
中小零細企業にとって、一寸先は闇ですね(つД`)
はれのひ騒動とか記憶に新しいですが、ああいうの日常茶飯事ですよね。
弊社も、気を引き締めていないと、いつそうなるかわかりません。
なんというか、これを書くにあたり、
「そういえば【はれのひ】どうなったんだろう?」
と思って調べたら
https://info-hachiouji.tokyo/harenohi201806
という記事を見つけました…。
【抜粋】
「はれのひが既に債務超過(資産をすべて売却しても、負債を返済しきれない)の状態になっていたにも関わらず、横浜銀行に嘘の決算書を提出し、3500万円もの融資金をだまし取ったという容疑による再逮捕になります」
3500万円の融資をだまし取るために、嘘の決算書を出して逮捕…。
カイジってマンガで、2000万円を得るために高層ビルの間に渡される鉄骨を渡るというシーンがありますが…。
なんか胸が苦しくなってきますね。うぐぅ。
ちなみに、「夜逃げ」とはいわゆる「いきなりいなくなる」という意味で使っているので、「夜」「逃げ」たのかどうかはわかりません。

この度、Smart動態管理が8.4.0にアップデートし、配送計画のCSVインポート機能がリリースされました。
次のような場合に便利です。
「Excelで配送計画を作ってるから、Smart動態管理に入れるメリット感じられなーい」
というそこのお客様!!
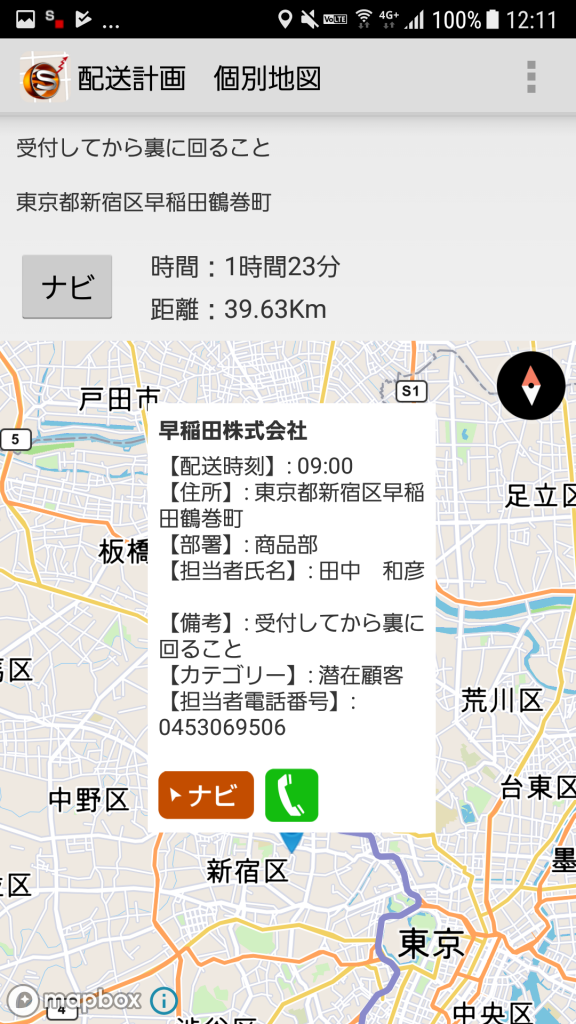
Smart動態管理に入れておくと、ドライバーさんのSmart動態管理アプリで配送計画が閲覧できます。
Excelなどで配送計画を作っている場合、その表を印刷したり、ドライバーさんが配送先の住所をナビに手入力したり、電話する際に電話番号を携帯に打ち込む、などの手間がかかってしまいますよね?
Smart動態管理アプリでは、ナビも電話もワンタッチでできます。
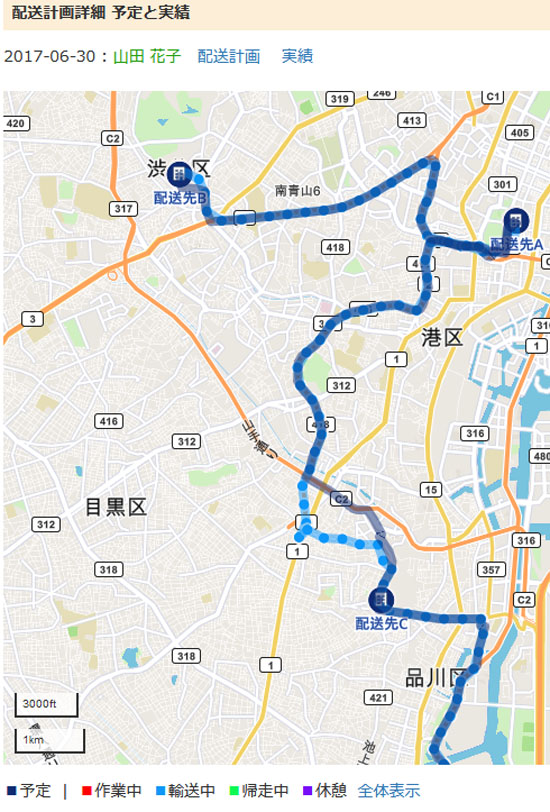
配送計画とドライバーさんが配送した実績を比較して、どこまで配送が終わっているかもわかることができます。
求貨求車サービスって何かって言いますと、トラックと荷物を運びたい人をマッチングするサービスです。
運送・配送業界の非効率はいろいろなところにありますが、荷物を運びたい人と、トラックがマッチしていない、という問題は結構大きなものです。
長距離とかだとこれが大きくって、例えば
「今日東京から仙台に荷物を運ぶ大型トラック」
がいたとすると、仙台から帰る時、積荷は空なんですよね。
この時、何か運べるじゃん!!ガソリン代、人件費、高速代、どうせ走るんだしもったいないじゃん!!
という発想に、もちろんなりますよね。
老舗サイトとしては、トラボックスさんという有名なサイトがあります。
http://www.trabox.ne.jp/
で、最近攻勢をかけてるのが
https://www.hacobell.com/
や
https://pickgo.town/
だったりします。
他には
https://movo.co.jp/
https://www.tranavi.net/
もう、とにかくめっちゃいっぱいある~!!!
なんですよね。
弊社はこういうのやらないの?とか言われることもあるし、こういうのを開発してくれと頼まれたこともあります。
私の考えとしては、将来的にはわかりませんが、現在は、動態管理をよりブラッシュアップしたものにする、または配送計画の精度を上げるなど違う課題を解決したいと考えています。
マッチングは、どこかほかのサービスさんに任せます…。
あれもこれもって手を広げるのは、多分、ソフトウェア開発に限った話じゃなくてあまりよくないと思っています。
一番ダメなのはファミレスみたいになっちゃうことじゃないですかね。
そこに行くと何もかもがそろうけれども、何もかもが中途半端…。(ただ、ファミレスは装置として価値があるから生き残ってると思っています。)
弊社は、おいしいそばだけ出すそば屋になりたいです。
特に、ソフトウェアの開発は、手がかかるし、メンテナンスも大変ですからね~。

「えっ 今更?」
と言われてしまうかもしれませんが、弊社のとあるシステムが、PHP7になりました。
わーい。パチパチパチパチ⊂(^-^)⊃
それにしてもですね、こういうサーバーサイドの環境の移行って大変なんですよね。
今回、弊社のTが行いましたので、私はノータッチですが。
本当に面倒なことだと思います。
幸いにも、コード部分にあまり書き直しが発生することはなかったのでよかったですが。
将来的に、こういう部分の面倒さが減る時代が来るといいなぁ。
プログラムがとあるOSやコンパイラの上で動くという仕組みである以上、どうしようもないのかもしれず、なんのアイデアもありませんが。

Gitクライアントって何使ってますか??
私は、実は昨日までCLI(コマンドライン)で使ってました。
Windowsのコマンドプロンプトで使うやつです。
その前まで、SourceTreeを使ってたんですが、SourceTreeがなんかの不具合で使えなくなって、直す気がなくなってCLIを使ってました。
CLIの利点がいくつかあって
・速い!!!!
・複雑なことをしやすい
・できるプログラマー感がある(笑)
ですね。
デメリットは
・ファイルの差分を見るのがめんどい!!
・視覚情報が少ない…
です。
これは私からした考えなので、ほかの人は違う意見だと思います。
しかし、今日、やっと思い立って、SourceTreeを直して、使いなおしました!!!
理由は…。
やはり、ファイルの変更差分を見るのに、GUIの方が圧倒的差があるからです。見やすいし、コマンドうつ面倒くささがない。
その差…っ!!圧倒的…っ!歴然…っ!!!
んで、ファイルの変更差分を見る、というのが私的には一番Gitでやりたいことなんだよなぁぁ。
そして、SourceTreeさんもなんだか早くなってる!!(現在のバージョンは2.5.5.0)₍ᐢ⑅•ᴗ•⑅ᐢ₎♡
とはいえ、コマンドラインでも操作ができたほうがいいときがありますね。なんかおかしくなっちゃった時とかの操作が、SourceTreeだとにっちもさっちもいかなくなる時があるからです。(´・ω・)
ちなみに、Githubご謹製のGitクライアントも試したことがありますが、SourceTreeの方が使いやすかったですね。
もし、ほかにオススメのGitクライアントがあれば、教えてください。
