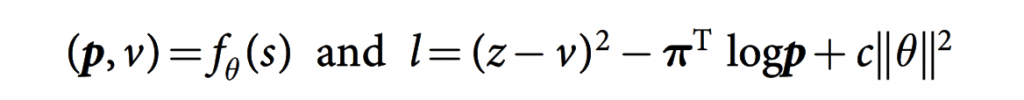昨日、PHPカンファレンス2025に行ってきました!
感想を書いておきます!
今回は6月にあるというのをすっかり失念していたので、危うくいかないところでした。
また、仕事が最近重めのプロジェクトがやっと終わったところで、プログラミング大好き人間の私でも
「週末ぐらいはプログラミングと離れていたい…」
と思っていたところだったので、ちょっと参加に迷いましたが、いつもなんだかんだ行ってよかった!となるので、重い腰を上げていきました!
結果、やっぱり行って200%よかった!です!
拝見したトークについて書いておきます。
皆さんがスライドを上げていてくれるので、とても便利で助かります!
①MySQL5.6から8.4へ 戦いの記録
私は最近はDBのことは任せているので、他の担当者の参考になるかな?という目線で聞いていました。
実際の体験記はやっぱり価値があります!
ゼロ日付気を付けないとですね…。
②PHP 8.4の新機能「プロパティフック」から学ぶオブジェクト指向設計とリスコフの置換原則
プロパティフックという機能ができるのは知らなかったので、勉強になりました!
後、スピーカーの方が
「リスコフの置換原則の『共変・反変』という言葉が僕は大嫌いなんですよ!」
と言われていたの、100%同意(笑)です。⊂(^-^)⊃
そう、『共変・反変』って何なん?と私も常々思います。
難しいし、日本語でも意味がわからないし。はんぺん?はんへん?
リスコフの置換原則を巡っては、私もこれがなんか難しく伝えられすぎているのでは?と思うことがあります。
いつかスライドのネタにしようかな。
③AIプログラマーDevinはPHPerの夢を見るか?
今はやっぱりAIでコード書けるの、どこまで行けるかは皆さんが気になるネタだと思います。
Devinはどうなのかな?と気になっていたので、聞いてみました。
「リーダブルコードを読ませて、これに沿ってリファクタして」
と言ってみて、
・何を学んだか、何に苦労したか
・指示の出し方は適当だったか
・自分で自分をほめてあげたいところ
・後輩に伝えたいこと
・挑戦したいこと
を聞く、というのは私の発想にはなかったので、面白かったです!
本当に、人間の新人プログラマーみたいな答えが返ってくるんですね(笑)
タイトルは有名なSF小説ですが、SFの世界になったな… と改めて思わせられました。
④設計やレビューに悩んでいるPHPerに贈る、クリーンなオブジェクト設計の指針たち
https://speakerdeck.com/panda_program/how-to-write-clean-objects
立ち見が多く、人気のあるお題なのかな?と思いました。
プログラマー同士会話するときの前提を合わせておくってだいじですね。
オブジェクト設計スタイルガイド、早速購入しました!!
で、オフライン参加の目的としては、やはり飲み会も大きな比重を占めております!
リアルにいろんな方の顔を見て本音が聞けるのは大きい!
プログラミングの話題だけでなくって、会社の話、転職の話、採用の話など、聞きたい話題がいっぱいです。
もちろんね、こういう知らない人だらけのパーティー、苦手!って人多いと思います。
私も苦手です。
でも思い切って話しかける!を毎年がんばってやっております。
今回の感想は、
「女性が増えた!」
ってことですかね。
PHP界隈は女性のPHPerさんがSNSとかで盛り上げてくれているからでしょうか?
嬉しいことです。
じゃんけん大会で名古屋のPHPカンファレンスのTシャツももらえました!
名古屋出身なので、これは嬉しい!

めちゃくちゃ大きいサイズでもらいました。XXXLとかかな?
さてさて、末尾ではありますが、弊社はプログラマーの勉強会参加も奨励しております!
休日に参加したら、その分「勤務」扱いになり、代休とお給料が出ます。(事前申請と許可は必要)
ぜひぜひ、話を聞くだけでも結構なので、弊社にご興味ありましたらご連絡ください!
採用情報はこちら↓
https://onlineconsultant.jp/recruitment/