はぁー 寒いような変な天気の日が続きますね。
早く、毎日30度以上の気温になる日々が来てほしいです…。(´ω`)
さて、前回↓
Alpha Go Zeroの論文の翻訳 その1
の続きです!
またまた、間違いなどありましたら、指摘してください。m(_ _)m
原文はこちら。
https://www.nature.com/articles/nature24270.epdf
今回から本格的な実装の話!わくわく。てかてか。
Reinforcement learning in AlphaGo Zero
fθがニューラルネットワーク。
(p, v) = fθ(s)
sは盤面の場所。
pはその場所にいく可能性。vはプレイヤーがsにいて、且つ可能性で価値。
pは1次元テンソルでaという動作を次に取る確率で
pa= Pr(a| s)
としてあらわされる。
vは0次元テンソルで現在のプレーヤーがポジションsに於いて勝利する可能性。
このポリシーネットワークとバリューネットワークの役割を組み合わせて一つにしたようなニューラルネットワークで、Residual Blockを含んだ畳み込みレイヤーで、batch normalizationとrectifier nonlinearities(ReLU Rectified Linear Unitではない?)はでできている。
Alpha Go Zeroのニューラルネットワークは新しい強化学習のアルゴリズムで、セルフプレイのゲームでトレーニングされる。
それぞれのポジションsからの動作の勝率πをMCTS(モンテカルロ木探索)でfΘを参考にして計算する。
この確率は、普通はニューラルネットワークから得た確率より強い動作を選択する。
MCTSは強力なpolicy improvement operator(訳せない…)として働くように見えるだろう。
探索を伴ったセルフプレイ…より強力になったMCTSベースのポリシーが手を選ぶ。
その時、ゲームの勝者zをバリューのサンプルとして動作する。
zはpolicy evaluation operator(訳せない…)とみなされる
我々の強化学習のメインアイデアは、探索者(MCTSのことだと思う)をポリシー改善のイテレーションの中で繰り返し使うことである。
ニューラルネットワークはp,vをπ、zに近づけるようにアップデートされる。
そのパラメーターは次のイテレーションに使われる。
MCTSはニューラルネットワークfΘをその計算のために使う。
それぞれのエッジ(s, a)は事前確率P(s, a)と訪問回数N(s, a)、アクションバリューQ(s, a)を保存する。
それぞれのシミュレーションはルートから始まって、葉ノードのstまで信頼上限(Q(s, a) + U(s, a),)が一番高い動作を選択していく。
信頼上限は、事前確率を訪問回数+1で割った数に比例する。
U(s, a) ∝ P(s, a) / (1 + N(s, a))
この葉ノードは一回だけ(P(s′ , ·),V(s ′ )) = fθ(s′ )を取得するために拡張されて、評価される。
それぞれのエッジ(s,a)はN(s, a)をインクリメントカウントするためと、これらのシミュレーションたちの平均的な(?)アクションバリューになるようにアップデートされる。
s,a→s‘とはシミュレーションがsからの動きaが最終的にs’に行きつくということを示している。
MCTSはセルフプレイのアルゴリズムのように見えるだろう。
MCTSはニューラルネットワークのパラメーターΘとルートポジションのsを渡され、そのポジションでの勝率に近い手πを算出する。
πはそれぞれの動作の訪問回数のべき乗に比例する。
ニューラルネットワークはセルフプレイで一手ごとに強化学習のMCTSを使ったアルゴリズムでトレーニングされる。
最初に、ニューラルネットワークはランダムな重みΘで初期化される。
続くイテレーションで、セルフプレイが続けられる。(図1a この図よくできてるのでぜひ参照してください。)
それぞれのタイムステップtでMCTS πt= α=θi-1(st) が繰りかえされるが、それぞれのMCTSでは、前回使われたニューラルネットワークの結果を使っている。
ステップTで最後。
探索の価値が終了の閾値まで下がったらあるいは最大の手の数を超えたら終わり。
ゲームは最終的な報酬である、-1か1を返す。
それぞれの手のデータは保存されている。
(st, πt, zt)
Ztはー1か1。勝者かそうでないか、ということ。
平行して、NNのパラメーターΘはずっと、(s,π,z)の値で次のようにトレーニングされる。
vがzに近づくように(vとzの間のエラーが少なくなるように)、pがπに近づくように。
パラメーターΘは損失関数l、勾配降下法(平均二乗誤差と交差エントロピーの合計)によって最適化されていく。
損失関数lの式。
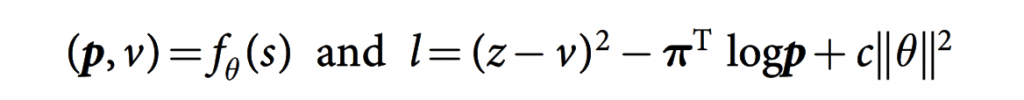
パラメーターcは、過学習を防ぐためのL2正則化のレベルためのパラメーター。
図1の説明(この図がよいので、原文を見てみてください)
図1a
プログラムはゲームを自分自身を相手に進める。s1,s2,…sTと手を進めていく。
それぞれのポジションsでニューラルネットワークfΘを利用してMCTS αΘが実行される。
手はMCTSの計算結果によって選択されていく。最後のポジションsTで、ゲームの勝敗zを算出する。
図1b
Alpha Go Zeroにおけるニューラルネットワークのトレーニングについて。
ニューラルネットワークはボードのポジションstをそのまま入力として受け取る。
ニューラルネットワークはstを入力すると、いくつかの畳み込みレイヤーにパラメーターΘと一緒に入力され、次の2つを出力する。
①pt(ベクトル(1次元テンソル))
このベクトルptは動作の確率分布。
②バリューvt(スカラ(0次元テンソル))
現在のポジションsからの現在のプレーヤーの勝率
ニューラルネットワークはpはπへの類似が最大になるように、vはzと比べた時のエラーをなるべく少なくしていくようにアップデートしていく。
新しいパラメーターは次のセルフプレイの繰り返しの時に使われる。
——————————————————————————————————————————————–
以上でReinforcement learning in AlphaGo Zeroの部分は終わり。
MCTSの計算で使うパラメーターをニューラルネットワークでアップデートしていくわけです。
ニューラルネットワークで使うパラメーターp,v,πはMCTSで生み出されるわけです。
MCTSとニューラルネットワークが相互に依存しながら進化しあっていくわけですね~。

Pingback: Alpha Go Zeroの論文の翻訳 その3 | Summer Snow